728x90
반응형
Unsloth 라는 기가막힌 라이브러리가 있다고 하여 바로 실행 해봤다.
아래 깃허브에서 원하는 모델 선택해서 Colab에서 바로 실행해 볼 수도 있음~!!
https://github.com/unslothai/unsloth?tab=readme-ov-file
GitHub - unslothai/unsloth: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory
Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
github.com
실제 실행해본 코드 첨부 해봅니다.
## 필요 라이브러리 설치
%%capture
# Installs Unsloth, Xformers (Flash Attention) and all other packages!
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
!pip install --no-deps "xformers==0.0.27" trl peft accelerate bitsandbytes
## Unsloth 셋팅
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
# 4bit pre quantized models we support for 4x faster downloading + no OOMs.
fourbit_models = [
"unsloth/Meta-Llama-3.1-8B-bnb-4bit", # Llama-3.1 15 trillion tokens model 2x faster!
"unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
"unsloth/Meta-Llama-3.1-70B-bnb-4bit",
"unsloth/Meta-Llama-3.1-405B-bnb-4bit", # We also uploaded 4bit for 405b!
"unsloth/Mistral-Nemo-Base-2407-bnb-4bit", # New Mistral 12b 2x faster!
"unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit",
"unsloth/mistral-7b-v0.3-bnb-4bit", # Mistral v3 2x faster!
"unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"unsloth/Phi-3.5-mini-instruct", # Phi-3.5 2x faster!
"unsloth/Phi-3-medium-4k-instruct",
"unsloth/gemma-2-9b-bnb-4bit",
"unsloth/gemma-2-27b-bnb-4bit", # Gemma 2x faster!
] # More models at https://huggingface.co/unsloth
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
## Data 셋팅 (Teddy 님 강의에서 사용한 Data 활용)
alpaca_prompt = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["instruction"]
outputs = examples["output"]
texts = []
for instruction, output in zip(instructions, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(instruction, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
from datasets import load_dataset
dataset = load_dataset("teddylee777/QA-Dataset-mini", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)
## 학습 준비
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
# num_train_epochs = 1, # Set this for 1 full training run.
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)
## 학습
trainer_stats = trainer.train()
# 추론해봄
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"CES 2024의 주제에 대해서 말해줘.", # instruction
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
학습에 사용 했던 데이터

학습 후 추론해본 데이터

그리고 그냥 llama 3.1 기본 모델에 똑같은 질문을 해봄
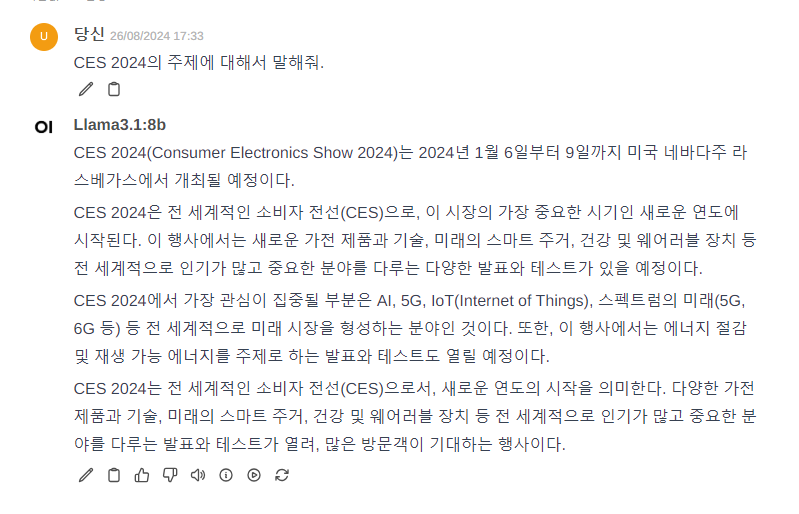
확실히 파인튜닝이 된 것으로 보임.
이제 내 데이터 잘 만들어서 해봐야겠다~
문서에서 llama 학습용 Data 만드는 법과 파인튜닝은 아래 영상 참고했습니다~
감사합니다.
https://www.youtube.com/watch?v=oZY0D8N6bC8
728x90
반응형
'AI' 카테고리의 다른 글
| 그림 제일 잘 그리는 AI - Flux 윈도우에 설치 (1) | 2024.08.30 |
|---|---|
| phi-3.5-vision 사용해 보기 (눈 달린 AI?) (7) | 2024.08.27 |
| 한글 더 잘하는 llama3 찾아서 ollama에 연결하기 (feat. Bllossom ELO) (4) | 2024.07.10 |
| 한국에서 만든 AI 서비스 : 뤼튼 (wrtn) 사용기 (무료 챗GPT) (0) | 2024.06.23 |
| Flowise 나도 따라해보기 (windows) (2) | 2024.06.13 |



